
This post describes how Spark functions as an ETL tool and compares Spark to other tools such as Ray, Beam, and Dask. This post strives to be a living document.
Spark in a Nutshell
From MapReduce …
Spark is popularly known as an open source implementation of MapReduce. MapReduce was designed as a solution for running analytics on large, distributed datasets.
Suppose we have a table of email addresses and we wish to compute the top 10 most frequent domains (e.g. yahoo.com) in the table. If the table lives in an SQL database, we can write a simple SQL query with a GROUP BY to solve the problem. But if the table is very large and stored across several machines, we’d need a MapReduce job: a Map from email address to domain (e.g. me@yahoo.com -> yahoo.com) and a Reduce that groups extracted domains and counts them.
In 2004, when MapReduce was first published, the MapReduce solution proposed above was novel. Research on MapReduce focused on tuning performance and support for generic query execution (to obviate the need to write explicit Maps and Reduces). By 2012, Spark and other tools had provided well-optimized SQL interfaces to distributed data. One could apply Spark SQL to the distributed setting described above and Spark would effectively auto-generate a MapReduce job for you. (Today, Spark will compile the Map and Reduce operations into highly-optimized bytecode at query time).
…to Interactive Cluster Computing
Spark is much more than a MapReduce platform. At its core, Spark is a distributed execution engine:
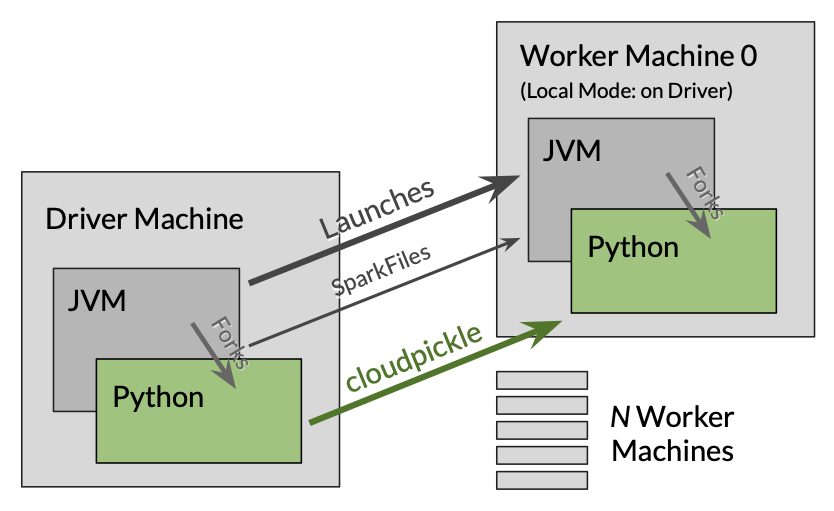
When you run a Spark job:
- Your machine, the Driver, gains interactive control of JVM (and Python) processes on cluster Worker machines. (Your local machine might host Worker processes when running in Local Mode).
- Code from the Driver is transparently serialized (e.g. via cloudpickle) and sent as bytes to the Workers, who deserialize and execute the code. The Workers might send back results, or they might simply hold resulting data in Worker memory as a distributed dataset. (The Workers can also spill to local disk). The user’s library code (e.g. Java JARs and Python packages) can be torrented out to Workers through the SparkFiles API (and usage of this API can be automated using
oarphpy). - Each Worker can independently read and write to a distributed datastore like AWS S3. This many-to-many strategy allows a job to achieve arbitrarily high levels of total I/O.
- Workers can join and leave the cluster as one’s job is executing. When workers leave (or a task fails), Spark will automatically try to re-compute any lost results using the available Workers.
- When dealing with input data that is already distributed (e.g. in Hadoop HDFS, Gluster, etc), Spark will use data locality information to try to co-locate computation with data. (This is a central feature of MapReduce: move computation to the data).
- Above, we noted that Spark can transparently distribute user code (e.g. functions, classes, and libraries) with each job run. If one needs to distribute a dockerized runtime environment with user dependencies, Spark offers integration with Kubernetes, which will transparently distribute, cache docker images for, and set up dockerized Workers on a per-job basis. This feature provides one of the easiest and most robust solutions for scaling a complete runtime environment from a single machine to a cluster.
- The overhead of Spark itself? Spark’s task execution latency adds mere milliseconds to network latency, and Spark serializes task results with the most efficient solution available (and for Python uses standard
pickleand notcloudpickle). Spark carefully manages JVM memory, reserving some for user code and some for buffering intermediate results. (The user can tune these settings on a per-job basis).
Spark versus …
Beam
Beam seeks to be a software architecture that abstracts away the underlying execution of an ETL job. Beam focuses on streaming workflows where Hadoop was once the de-facto tool: crunching log files using custom Maps and Reduces. Beam offers a modern take and offers specialized support for streaming sources– e.g. logs straight from a webapp or Kafka cluster. Beam is a favorite among Google Cloud sales engineers (i.e. their auto-scaling Dataflow offering) and Google Research engineers who lack a Python-focused ETL tool due to Google’s internal deprecation of MapReduce (public examples: 1 2 ). Beam was first published as Google Dataflow.
Beam offers a feature matrix to roughly compare it to others, including Spark. There are a number of factors that make Spark preferable to Beam for ETL.
Beam’s Interactivity is an Extra
To iteratively develop a Beam Pipeline in a notebook environment, Beam requires using a specialized Interactive Runner API. Cached data from partial execution, if any, is always spilled to disk and requires expensive text-based serialization. Unlike Spark Dataframes, Beam PCollections are incompatible with pandas.
Notebook-based iterative development typically helps a user write not only correct code but also helps the user discover outlier data cases quickly and interactively. A Beam user who simply needs working code might be fulfilled with the current offering. However, a Beam user who needs to examine basic statistics (e.g. the range or mean) of a value during a full or partial run of a Pipeline must undertake much more effort than a Spark user, who can use either Spark’s Dataframe API, or load a piece of data into pandas for fast analysis and graphing.
Performance
Beam’s core abstractions are effective at isolating the user program from the execution engine… but at what cost? These abstractions appear to impart a considerable performance penalty in benchmark of common jobs.
Alpha-level Support For SQL
SQL is often a highly efficient substitute for Python in ETL jobs: SQL can result in far less code, SQL can be much more readable than a set of Python functions, SQL can be portable to other contexts (e.g. queries can also run in Presto, Hive, or BigQuery), and runtime optimization of SQL queries is both well-studied and built into most engines. In 2019, Beam provided alpha-quality SQL support for its Java API only.
Per-job Dependencies
While Beam does offer an affordance for shipping your own Python library with a job, your library must have a setup.py, and the library cannot be updated live during job execution (as can be done easily with oarphpy.spark in a Jupyter Notebook)). Unlike Spark, Beam does not offer distribution of arbitrary binary files; the user would need to manually copy the file to the job’s scratch directory on distributed storage.
Ray
Before Spark grew into an ETL tool, the authors sought to build a general library for distributed systems using the Akka Actor model. Akka today serves as Spark’s networking layer and powers Driver-Worker RPC as well as fault tolerance.
Ray began with similar aspirations and also leverages an actor-based model for fault tolerance and distributing compute. Ray, like Spark, also originally targeted use cases in Machine Learning. While Spark includes its own built-in distributed storage engine (BlockManager) for RDDs and DataFrames, Ray relies on Redis to provide per-job distributed storage.
While Ray can indeed run MapReduce jobs, Ray lacks a few key features to make it a viable ETL tool:
-
Data Locality: Ray does not try to co-locate computation with data, so it cannot function as an efficient general MapReduce or database solution.
-
DataFrames and SQL: Ray has nascent DataFrame support, which is now part of the Modin project. Support for SQL on data is currently in only a roughly planned state.
-
Distributing Artifacts: Like Spark, Ray leverages
cloudpicklefor distributing user code to workers. However, there’s no affordance for distributing a user library with an individual job. The user must have a shared filesystem / temp store available, or must somehow leverage Ray’s central Redis-powered distributed object store.
Ray’s strengths are in reinforcement learning and hyperparameter search: two use cases that are heavy in computation and light on data.
Dask
Dask seeks to offer the most performant multi-machine solutions for common Dataframe- and Matrix-based tasks in Data Science. While Spark supports similar use cases through Spark Dataframes as well as Spark MLlib, Spark’s APIs are bespoke while Dask builds behind existing Pandas and Scikit-learn APIs.
While Dask might be an effective tool for data analysis itself, Dask lacks a few key features important to ETL:
-
SQL Dask can read and write from standard databases (as can Spark through JDBC), but Dask can’t perform SQL on the data backing a DataFrame. One must use the Pandas API (which can make group aggregations and joins difficult to express).
-
Data Locality: Dask is locality-aware once you get data into it, but it does not support HDFS-compatible distributed datastores as does Spark and most of the Hadoop ecosystem.
-
Distributing Code: Dask Bags support the same sort of
cloudpickle-powered computation possible with Spark RDDs, but Dask lacks a facility for distributing custom user libraries.
That said, Dask offers a few features that Spark lacks:
- No JVM required
- Inclusion of futures, which sometimes preferable for CPU-heavy use cases (e.g. jobs one might otherwise run on Ray).
- Dask’s
delayedAPI can make it easier to run distributed stochastic gradient descent (SGD). While Spark has similar support for parallel SGD, the RDD API complicates synchronization.