
ETL and Spark
Data wrangling is a key component of any machine learning or data science pipeline. These pipelines extract raw data from logs or databases, transform the data into some desired format, and then load the results into a new data store or directly into a training pipeline. ETL might be as little as a line of code or as much as a full-fledged software library. Indeed, ETL is a key source of technical debt in machine learning systems; moreover, the success of a project can sometimes depend on how quickly engineers can iterate on ETL code and leverage data available to them.
Spark is one of many tools for ETL (and might be one of the best). Spark is popularly known as a distributed computing tool, as it is one of several open source implementations of the MapReduce paradigm. Indeed, parallel computing is key for ETL: executing a job on 10 cores instead of 1 often makes the job 10x faster.
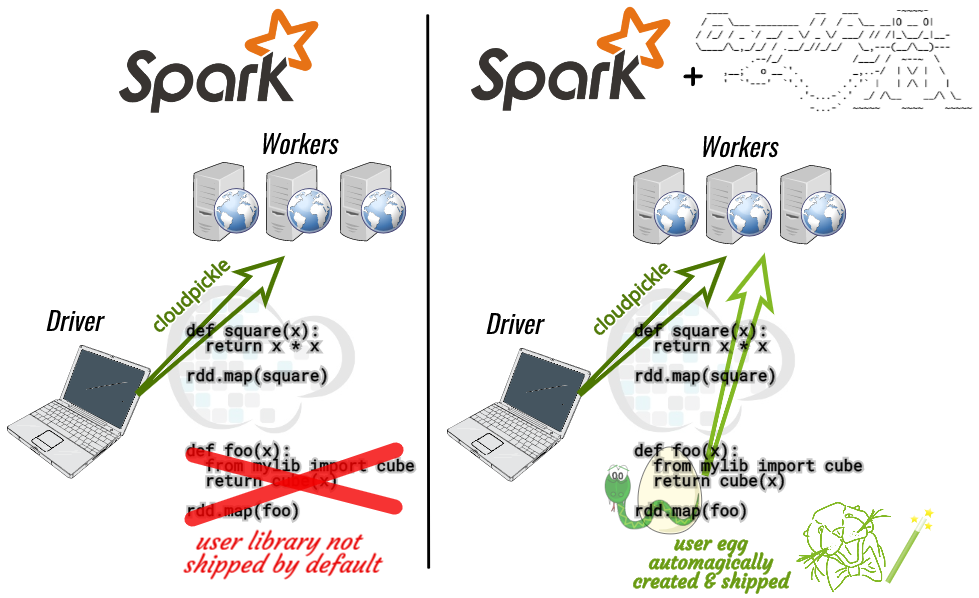
One differentiator between Spark and traditional MapReduce is that Spark supports interactive development of ETL programs in Jupyter or Google Colab notebooks. A key enabler of this feature is cloudpickle, an advanced code-oriented serialization library (versus pickle, which is data-oriented). The cloudpickle package supports serializing lambda functions, code defined in the __main__ module (e.g. a Jupyter notebook kernel or Python interpreter session), and even dynamically generated classes. When you run a Spark program, part of your code is serialized via cloudpickle in the local driver Python process, sent to remote worker Python processes, deserialized there and run.
But what if you want to use a library of your own Python code in your job? What if you want to make local changes to that library (e.g. pre-commit modifications) and run that modified code in your Spark job? Spark provides a pyFiles configuration option for including Python Egg(s) with a job. (Spark even provides caching and torrent-based distribution for these per-job data files). However, traditional use of the pyFiles feature requires user configuration and/or a custom build step. This article demonstrates how to automatically include with a Spark job the library containing the calling code using oarphpy.
Below we embed a demo notebook provided as part of oarphpy.