
Forward
This post was written as partial fulfillment of the requirements for the Fall 2024 UC Berkeley LLM Agents MOOC (also known as CS294/194-196).
Why has interest in Large Language Models (LLMs) and LLM Agents exploded in the past few years? What is the underlying research that has changed the technological landscape? The aforementioned course focuses on LLMs and Agents without providing much background on machine learning or LLM particulars. This post seeks to provide (briefly) that missing connection to machine learning and to highlight the key research results that supplant today’s LLM Agents.
LLM Foundations
What is an LLM?
The rise of LLM Agents can be seen as a consequence of seminal progress in the
construction of Large Language Models (LLMs). Like any trained
supervised learning model,
an LLM seeks to approximate (or “learn”) the behavior of a function y = f(x) from a
training set of exemplar input-output pairs (x, y). Most LLMs today, including the
massively influential OpenAI GPT models such as GPT-2,
seek to emulate a “next-token-prediction” function (i.e. “next-word-prediction,”
where most words constitute 1-2 tokens). For example, given an input
string such as "the cat jumped over the ", the LLM would seek to learn that
the next word (or token) in the string should be "dog".
Under the hood, most implementations of LLMs today use neural
networks based on the “Transformer Architecture.”
These neural networks are powerful sequence-to-sequence learners— where the
input-output (x, y) pairs in the training set are full sentences,
sequences of pixels (i.e. images), or time-ordered waveform datums (i.e. audio
data). Since neural networks take numeric data as input, LLMs must first
tokenize text input into
a sequence of well-defined numbers. For example, the word "hello" might
be the token number 24912 (according to the popular tiktokenizer
library), and the string "hi cat" might be the numeric sequence of tokens [3686, 9059].
A tokenizer itself is a bijective mapping between strings and numbers. Thus an LLM model
will “encode” string input to numbers, learn / predict sequences
of numbers, and then “decode” those numbers to produce a final output string.
Most LLMs also effectively implement (as part of the Transformer Architecture) a
probabilistic model of words (or tokens). Thus for any given input string, such
as "the cat jumped over the ", the LLM will actually infer a probability distribution
over possible next-word completions. For example, the word "dog" might have
the highest probability (e.g. 51%), but the word "mouse" might also have
substantial probability (e.g. 10%). To generate a complete output (i.e a
full sentence), most LLMs will generate (or “sample”) a single token at a
time based upon all prior tokens (i.e. both the input text and partial output
as the LLM generates the string). Note that since each token is a “sample” from
a probability distribution, an LLM can generate more than one distinct output
for any given input (and such outputs can be ranked by total probability).
The LLM Agents that we discuss below tend to use LLMs trained on massive numbers of strings containing question-answer pairs, where a question could be as simple as “what is 1+1?” and the answer string might be “the answer is 2”. While these training sets typically include trillions of tokens of arbitrary text from the internet to support basic language understanding, they also include specialized text such as corpora of grade school math word problems.
To further explore the underlying details of LLM model implementations, the reader should consult the video tutorial of Andrej Karpathy’s re-implementation of GPT-2 from scratch as well as the related Nano GPT code.
How can LLMs Perform Reasoning?
A key phenomena leading to the success of LLM Agents is the ability of LLMs to perform well on question-answer tasks that emulate human reasoning. To elicit such phenomena, good question-answer pairs (i.e. training data) or questions (i.e. user prompts at inference time) should exemplify “chain-of-thought” reasoning: one or more sentences where the speaker “shows her work.” See a key example below:
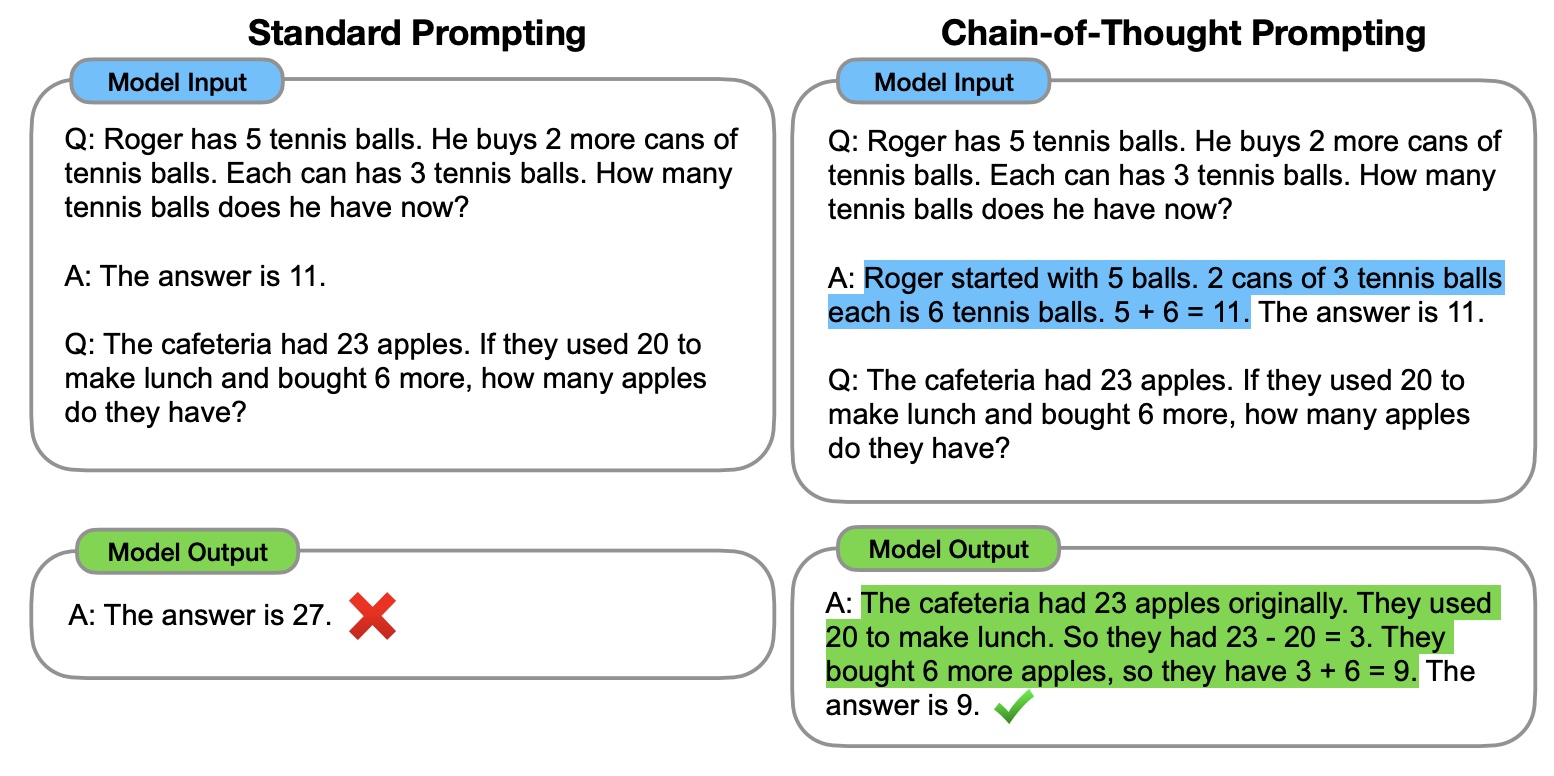
This technique of “prompting” or formulating inputs (and/or labeled outputs) serves a fundamental basis for LLM agents to:
- accurately perform simple arithmetic and logical synthesis (with relatively high accuracy);
- break a larger problem (which might be summarized in a single sentence) into smaller, detailed components (where each part or step might be several sentences);
- use “tools” such as arbitrary programmatic functions (e.g.
pythoncode) using textual descriptions of the APIs of the functions as well as demonstrations of the functional behaviors.
In particular, “chain-of-thought” text can be provided not just as training data, but also solely as part of the user prompt (i.e. at inference time) to help elucidate desired reasoning that might not appear in the training data. For example, a user prompt might include text demonstrating uses of a programmed function written well after the LLM model was trained. Thus the “chain-of-thought” technique unlocks substantial extensibility of trained LLMs (including closed-source, proprietary LLMs such as OpenAI’s GPT).
The initial research on “chain-of-thought” reasoning has inspired a variety of subsequent study, including the observations that:
- for more complicated reasoning tasks, premises must be provided in logical order (i.e. as a human would expect) for LLMs to succeed;
- breaking down larger tasks using “least-to-most prompting” helps LLMs handle larger tasks despite the longer strings (i.e. number of tokens) such inputs and outputs entail;
- for very large tasks, key pieces of information should be near the beginning or the latter half of the text or the LLM may not see the “needle in the haystack”;
- for game-playing and extremely intense reasoning tasks, LLMs can benefit from seeing small snippets of much larger solutions in order to “learn shortcuts” like humans do.
But can LLMs reason reliably? As described in the previous section, most LLMs “sample” or generate a single highly-probable answer for any given input. But that generated answer can be wrong! In the context of “chain-of-thought” prompting, some research has explored measures of self-consistency, where the LLM generates several explanations (i.e. chain-of-thought answer sequences) and some simple aggregation (e.g. majority vote on a final component of the answer) can help boost correctness on benchmarks. However, the issue of LLM reliability (and thus LLM Agent reliability) is still an active area of research.
Finally, note that in this section we do not seek to define “reasoning” absolutely, as researchers are still actively debating whether LLMs actually do reasoning:
Instead, here we seek to qualitatively describe useful LLM phenomena that mimic human reasoning and that (importantly) has given rise to the impactful LLM Agent work described below.
LLM Agents
What is an LLM Agent?
Software agents, such as the 1966 text chatbot ELIZA, interact with human users and/or the wider environment through a text-based (or similar) interface. These environmental interfaces can include more formal REST APIs or other programmatic APIs. The interface (or tool) must simply accept text as input and return a textual representation of the result on the environment. Software agents encapsulate the reasoning and algorithms needed to use these (text-based) interfaces to accomplish some goal (e.g. answer a question for a human user).
A rough definition of an LLM Agent is a software agent “that has non-zero LLM calls”. Thus an LLM Agent is simply a software agent that leverages modern LLM technology to choose how to interact with the environment. LLM Agents entail combining the chain-of-thought prompting and reasoning techniques described in the previous section with interfaces to the environment— this combination gives the LLM the ability to act. Research systems such as ReAct have demonstrated how this synthesis of LLMs, prompting techniques, and tools gives rise to LLM Agents that are successful at solving complex tasks:

A related thread of current research focuses solely on improving the abilities of LLM Agents to use existing software-based tools and APIs. ToolBench is one such influential project seeking to improve how LLMs can achieve fast and effective tool learning. The Toolformer study furthermore shows how an LLM Agent can reason to choose the best tool among a suite of tools. Today, many LLM services such as OpenAI GPT offer formal tool APIs where the user can simply include a text-based description of their own program’s function(s) alongside the input prompt, and the OpenAI LLM may reply with the choice to invoke those function(s).
Building High-Quality Agents
Memory and Retrieval Augmented Generation (RAG)
LLM Agents are most powerful when they have access to a high-fidelity representation of the environment’s current and past states (or memory), which can include the results of the LLM Agent’s own actions. For example, an LLM Agent may need access to its lengthy chat history with an end user. Furthermore, LLM Agents often benefit from access to ever-expanding content from the internet; indeed, some estimates show each day about 15% of all web searches target new content.
Retrieval Augmented Generation (RAG) is one of the most popular and effective ways to empower LLM Agents with memory. While the seminal work on RAG outlines a complex, end-to-end-optimized pipeline, many systems today employ relatively simple vector databases to serve as a memory component of the overall system:
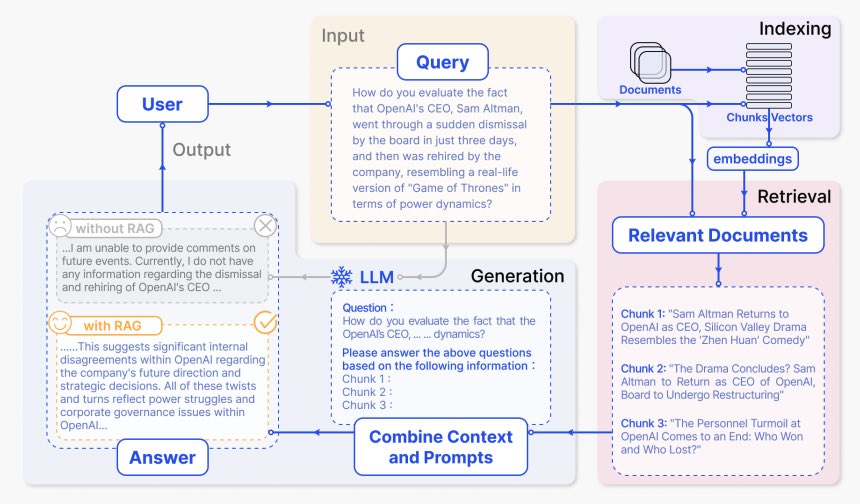
A RAG system will first ingest “documents” (i.e. chat history, content from the internet, or other useful data) and encode them into embedding vectors using a model very similar to an LLM (i.e. an LLM with a somewhat different “inference” procedure). At query time, the LLM Agent will compute similar embedding vector(s) for the query and match these vector(s) against all vectors in the database. (Note that this vector search operation is well-studied, is very fast, and there are ubiquitous implementations available). The matched vectors thus indicate relevant “documents” (e.g. specific chat history messages, individual web page snippets, etc.) that should be included as context to the LLM that generates the agent’s final response (and/or action). Therefore, the “retrieved” documents are added to the LLM input to “augment” the “generated” final response.
Optimizing Agents
For most supervised learning systems (including LLMs), the most effective way to optimize performance is to grow the training data set and to re-train the model. However, this approach is cost prohibitive for most LLM Agent developers because:
- basic training can cost as little as tens of US Dollars (USD) when done very, very efficiently but more typical, extensive training typically costs at least thousands to millions of USD (for GPU hardware, compute, and electricity);
- training data can be expensive, and the particular training datasets for top-performing LLMs (such as GPT-4) are not publicly available;
- re-training can sometimes fail (due to e.g. overfitting) and requires a distinct skillset to get right.
For LLMs (and in particular LLM Agents) careful tuning of prompts can significantly improve performance; moreover, researchers have explored automating the process of prompt tuning. In particular, DSPy has successfully helped improve a variety of agents through a novel blend of prompt engineering and reinforcement learning.
Further Reading
The content of this post focuses on topics in the early lectures of the Fall 2024 UC Berkeley LLM Agents MOOC. For more on LLM Agents, consult the course. For complete LLM Agent systems and frameworks, consult:
- appendix A of the AutoGen paper for a list of modern LLM Agent frameworks;
- OpenHands for code-generating LLM Agents;
- TapeAgents for a timeline-centered LLM Agent framework;
- LlamaIndex for an industrial LLM Agent platform.
Endnotes
- This post assumes only very basic machine learning knowledge. For survey of the most cutting edge machine learning research (which includes LLMs and more), see this collection of papers from Ilya Sutskever.
- OpenAI’s GPT-3 was trained on over 45 Terabytes of text.
- For a detailed discussion of relevant agents in Artificial Intelligence, see Lecture 2.
- Jerry Liu of LlamaIndex during Lecture 3.
- See for example
pgvectoror Rockset. - DSPy’s success stories include beating human expert prompt engineers as well as empowering a University of Toronto team to win the MEDIQA competition.